

How Feasible Is Uploading It to Our DNA?
Humanity has made incredible technological advancements since the 20th century. One of the biggest problems we have faced during this process has been how and where to store all the vast amounts of information and data we produce. But what if the solution to this problem was right in front of us all along?
The artificial intelligence sector, which has been on our minds for some time, continues to make headlines with the major breakthroughs that have taken place in recent years, with a significant part of its growth owing to data science.
Where are the data that power artificial intelligence stored today, and how are they stored? And what difference can DNA molecules, which are not even visible to the naked eye, make?
Most of our data is stored in the devices we use and on servers owned by some companies. However, this method is not very practical in the long run.

Our personal data is stored on the hard drives (HDD) of our computers and on flash memory cards in our phones. Data created or used in applications and websites, on the other hand, is stored on the servers that these applications and websites are connected to.
Because servers accumulate data for thousands or millions of people, it is necessary to note that more storage space is needed as time passes.
Mega companies such as Microsoft, Google, and others are buying more storage space to solve this problem. However, constantly having to increase storage space can cause problems for these large companies with many customers, and they may need to build new buildings for more storage space.

It would not be wrong to say that Microsoft and Meta are currently the companies most troubled by this problem. In 2019, Microsoft detailed the DNA data storage method in an article and announced its first DNA storage system to be used.
While Meta has not yet signaled in this direction, the company is famous for building data collection centers around the world to solve this problem.
Imagine all the social media platforms you use. Think about how many tweets, stories, posts, photos, and videos you see every day. Even for the daily content we consume and produce, we need a lot of storage space.
This situation applies to the other 5 billion people who already use the internet like you. When you take this reality into account, you realize how big the problem actually is.
Perhaps the most interesting idea put forward to solve the data storage problem is to use “DNA molecules!”

In 2013, genetic scientists George M. Church and Nick Goldman began working on data storage in DNA spirals by storing 1 MB of data. This method, which was further developed in the following years, eventually revealed that DNA has the potential to store a lot of data for 700,000 or 1,000,000 years.
According to scientists’ estimates, 215 million GB of data can be stored in 1 gram of DNA…The idea is that it would be possible to store all the knowledge and data that humanity has produced so far in a small room using this technology.
Now, let’s consider how this idea could be implemented through genetic engineering.
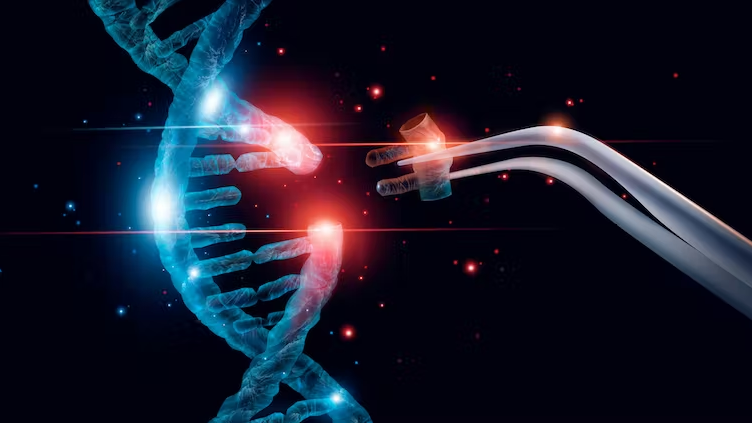
DNA molecules, which consist of nucleobases called adenine, thymine, guanine, and cytosine, are not easily accessible structures. First, an enzyme is selected. Then, this enzyme is manipulated in the laboratory, adjusted to target a specific DNA sequence, mixed with other enzymes if necessary or subjected to mutation through various methods, and finally released towards the target. In this way, the desired changes are applied to the desired DNA sequence.
For this method, a storage area that does not harm the enzyme and an injection tool are also required. For this purpose, thinner syringes than normal syringes and DNA tubes that prevent the substance from being affected or contaminated by the external environment are preferred.
At each step of the process, the necessary sensitivity and careful handling of the enzyme must be demonstrated, and the parts of the DNA to be edited must also be edited with the same sensitivity and care. If we think of enzymes as data folders and use them, it will be possible to store data in DNA.
This method can contribute greatly not only to data science but also to every field of science, as well as to its advantages, there are also some disadvantages.
One of these problems is that the cost of storing data in DNA is very high. While the cost of storing 1GB of data is currently $1,300, the cost of storing 1TB of data is currently $1,300,000. Scientists aim to overcome this problem over time and reduce the cost of storing 1TB of data to a small amount like $1.
Another problem is the possibility of the stored data being corrupted due to radiation and similar problematic factors. It is still unknown whether the data in the DNA as well as the data in our actively used devices will be safe in the event of a nuclear disaster or a major space event such as a large solar storm.
Additionally, DNA molecules are complex structures, and it requires a lot of precision and attention to detail to manipulate them



